Warning: The following post contains the elitist musings of an ivory tower professor who has only professed at major research universities, who attended a selective liberal arts college & received his doctorate from an Ivy league institution (well… a branch of one… Teachers College at Columbia).
A while back, I wrote a post on “ed schools” the point of which was to show the shift in production of degrees that had occurred between the early 1990s and late 2000s. When I wrote that first post, ed schools were coming under fire from DC think tanks like the National Center on Teaching Quality (NCTQ), which seemed largely unable to understand the most basic issues of degree production in education (I’m unsure they’ve learned much since then!). And now, it would appear that our esteemed U.S. Secretary of Education has decided that ed schools and teacher preparation will be of primary interest in the second term of this administration.
The problem as I previously indicated, was that most of this rhetoric about ed schools and their supposed failure of society and production of generations of ill-equipped American youth, is that the rhetoric of “ed school” assumes a static definition of ed school – rooted in a 1950s to 1970s characterization of the regional public teachers college, and built on an assumption that teachers obtain their training and a teaching credential – for the one thing they teach – through a single institution as the core of their undergraduate education. Being “teachers colleges,” these schools are obviously lax on admission standards, have curriculum that is neither academically rigorous nor practical, etc. etc. etc. (the conflicting rhetoric in this regard is fun to follow – too much theory… no practical application… but not academically rigorous, etc.), and well… simply must be replaced by a vast set of alternative routes/pathways/programs!
In short, the vast majority of the critique of teacher education assumes this monolithic AND STATIC entity of teacher preparation housed in state colleges and universities. Emporia state in Kansas – that’s you! Monclair in NJ – that’s you! West Georgia – you too! And those state flagships with teacher prep programs? Damn you Rutgers, Michigan, Illinois for producing increasing numbers of underqualified teachers! The wrath of NCTQ and now Arne Duncan will be upon you!
But degree & credential production in education has not entirely been static over time. In fact, anything but! There are clearly emerging trends. And if we believe that there really has been a decline in the academic quality of those receiving credentials in education, it would behoove us to take a close look at those trends. But since no-one else seems to be doing that – especially not NCTQ – I figured I should take another shot at it.
A couple of key points are in order. FIRST – it is important to understand that these days, many initial teaching credentials are already granted through alternate routes outside of undergraduate programs and to individuals with degrees in fields other than education. In addition to non-degree alternate routes which I cannot even capture with the data in this post, many initial teaching credentials are granted through graduate programs – at the masters degree level and an even larger share of additional – second/third credentials received by practicing teachers are obtained through graduate programs. Individual teachers may have collected a handful of different credentials, all from different institutions.
So, let’s take a look at undergraduate and masters degree production trends.
Undergraduate Training
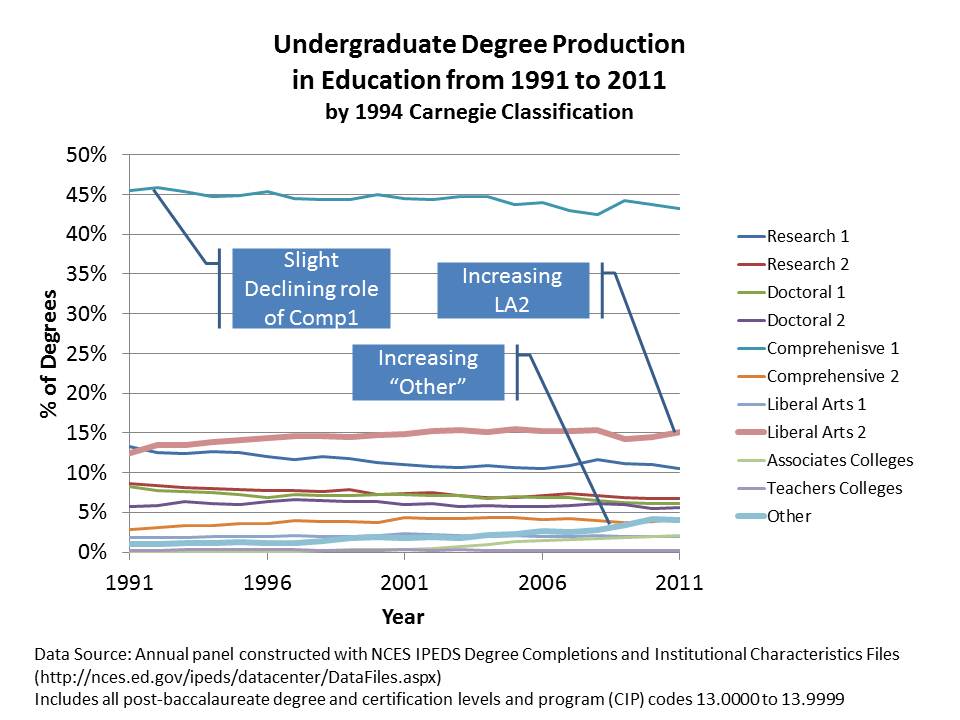
Undergraduate degree production in “education” fields generally (most of which involves teacher preparation) has been most stable over time. Using 1994 Carnegie Classifications (the most stratified system of Carnegie classifications of the past few decades: see end of post for definitions), we see that the percent of degrees being produced by what were the public “teachers colleges” (Comprehensive 1… as opposed to those labeled as “Teachers Colleges”) still hold the lions share, but have declined over time. Research Universities which produced around 14% in 1990 now produce closer to 10% (those are your state flagships & major private universities). So… the major traditional public college and university role is declining slightly in market share.
That loss is being picked up by what is actually a very small subset of colleges – that also tend to be relatively small, and not so prestigious colleges. These are the “LA – Liberal Arts 2” colleges. It’s quite striking that growth in this subset is sufficient to shift the market shares of major state universities and comprehensive regional colleges. Incidentally, LA 2s were among the first to expand rapidly their production of online and distance MBAs… around the same time they started tapping the ed market. (this period overlaps with a trend among financially strapped, less selective colleges making the move to change their name to “university.“)
Patterns are also relatively stable by the Barrons’ competitiveness ratings. Notably, colleges right in the middle of the competitiveness ratings have the largest market share. I know this conflicts with reformy ideas that all ed degrees are produced by the worst colleges – but at the undergrad level, it’s a pretty normal distribution. Competitive colleges have a consistent 50% market share. Indeed, they are not the top third. They are also not the bottom! They are… the middle… as one would expect for a profession with modest (at best) earnings expectations.
The next two categories out from there – one up (very) and one down (less), have just under 20%. But, the “less competitive” group seems to be showing an uptick (they are also heavy on those LA2s!). Highly Competitive and Non-Competitive are also relatively comparable, but with non-competitive slightly outpacing highly-competitive.

Masters Degrees
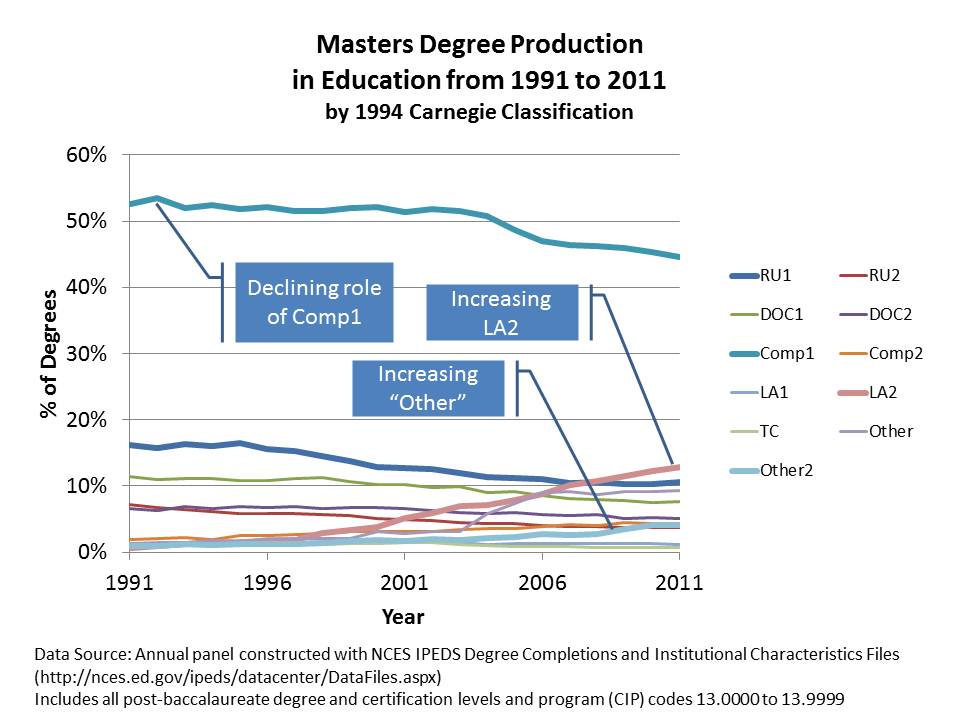
It’s in the production of masters degrees where the real fun stuff is happening. First, let’s take a look at what’s been happening across institutions by type. Note that Comprehensive colleges were, in large part, designed to deliver bachelors and masters degree programs and many from early on had large education programs and teacher preparation programs in particular. But we see in the figure below that the market share of masters degree production for Comp1s has declined over time. So too has the market share for masters degrees for Research Universities (including state flagship universities).
Amazingly, it’s those LA2s again that have risen dramatically in degree production. These lower tier liberal arts colleges (we’re not talkin’ Williams, Haverford, etc… which are LA1s. Those schools aren’t crankin’ up masters in Ed… and they’re also not changing their name to Williams University, etc.), have become the second largest producers of masters degrees in education. Bear in mind that liberal arts colleges, as classified in the 1990s, were never really intended to be handing out graduate degrees – no less massive numbers of them. LA2s have gone from only about 1% of ed masters production in 1990 to over 10% by 2011.
The next figure reclassifies these schools by the competitiveness of their undergraduate programs (since we lack competitiveness measures for graduate programs). What we see here is that masters programs housed in “LESS COMPETITIVE” undergraduate colleges are the ones that are creeping up in market share. To a significant extent, these are online, credential granting programs run through LA2s.
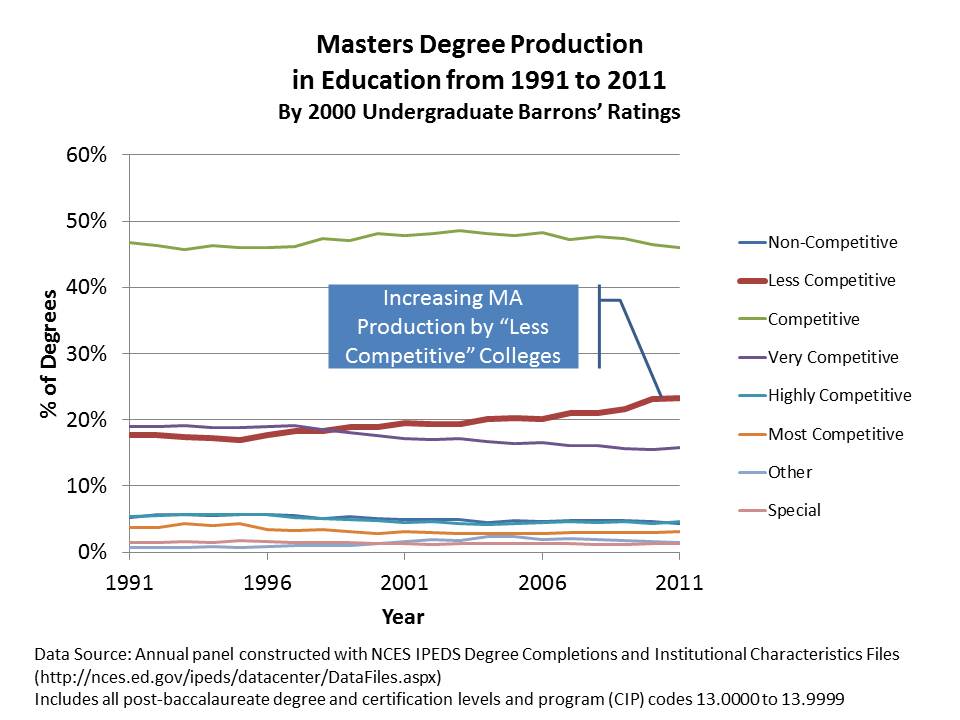
So, what we have here, is a rather dramatic expansion of graduate credentials in education being handed out by what some (including myself) might characterize as relatively low quality, non-selective undergraduate institutions that were never meant to be handing out graduate degrees to begin with. But perhaps that’s just my ivory tower, Research I perspective.
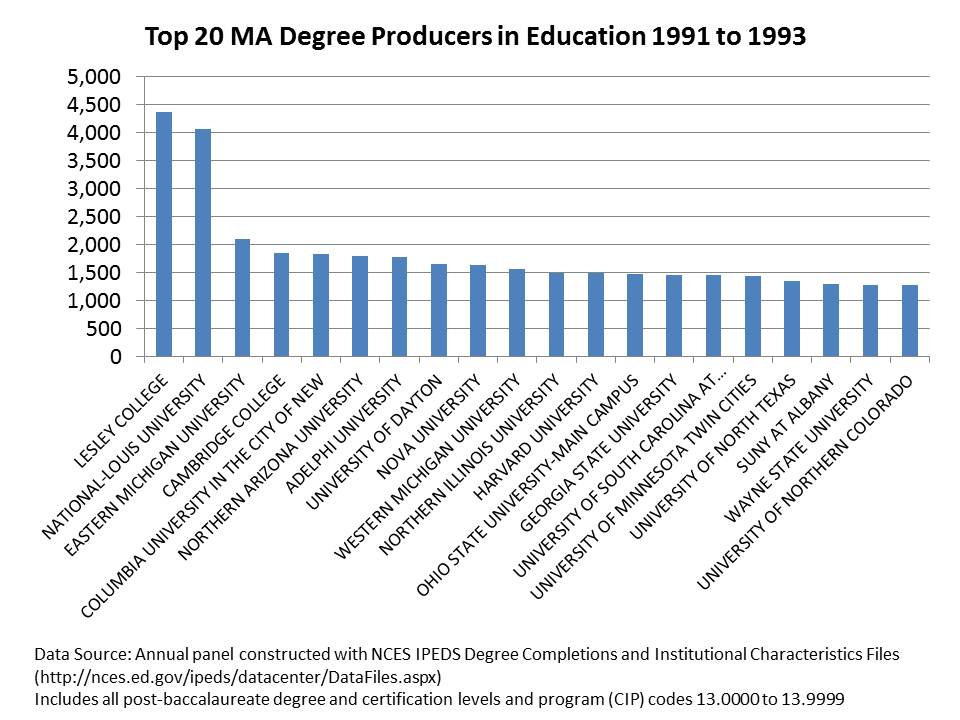
Now lets take a look at the top 20 Masters degree producers in the early 1990s and then in the most recent three years. In the early 1990s, the largest producers were crankin’ out a few thousand over a three year period. These included some early entrants – pre-online era – to the degree mass-production game like Lesley College and National Louis U. But, there were also many programs housed in brick and mortar public universities in the mix, including both state flagships (UT Austin, Ohio State) and other pretty solid academic schools (Harvard, Columbia/TC). Arguably, these [the public colleges in particular] are the schools now taking the brunt of the blame for the state of teacher preparation – Northern Arizona, Northern Colorado, Eastern Michigan, etc.
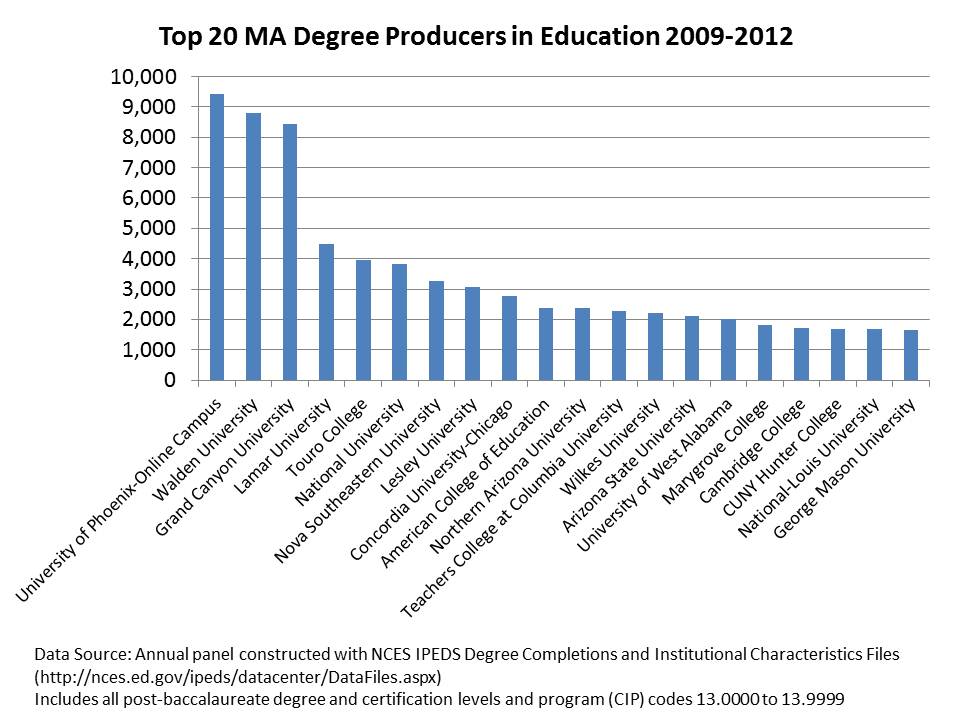
But who has actually been crankin’ out the masters degrees and credentials in recent years? And, if there is a decline and pending crisis in education training/preparation, who might instead be to blame? Below is the more recent production of graduate degrees/credentials. First and foremost, we’ve now got schools crankin’ out over 3,000 per year – or 9k per 3 years. Phoenix, Waldon and Grand Canyon together produce more masters degrees than many of the next several combined. There is a substantial gap in production before one reaches the first traditional teacher preparation program on the list.
Is it possible that the emphasis on traditional “ed schools” within state boundaries as the obvious source of our problems is misplaced?
Graduate Degree Production in Educational Leadership/Administration
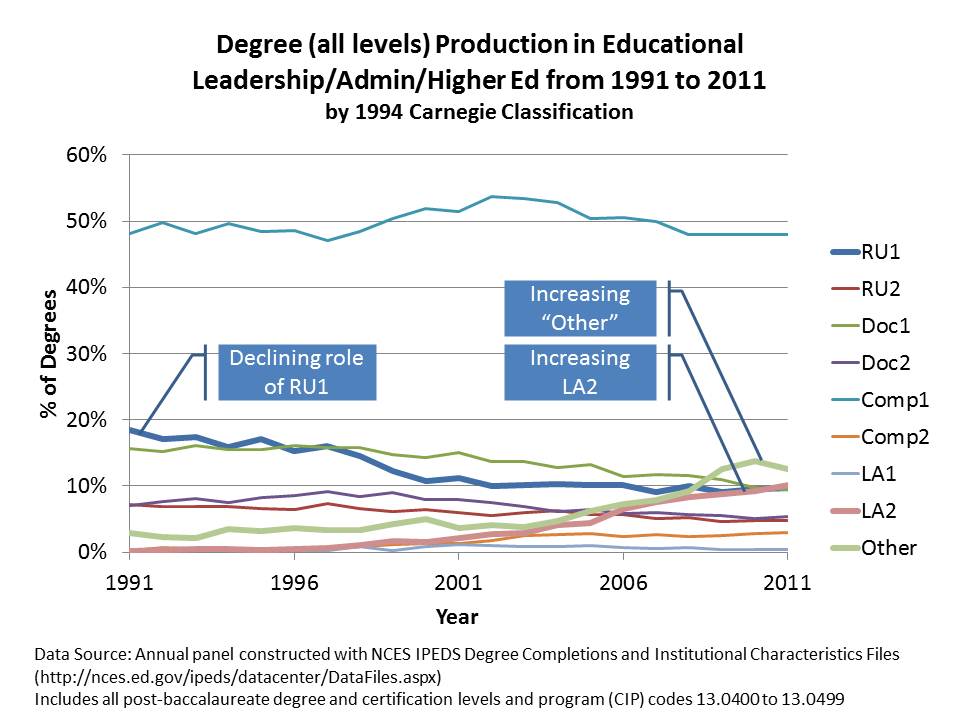
I’ve got one last bit to address here and that’s training in educational leadership/administration, a topic I’ve written about in my academic publications (see below). Degree production in educational leadership has followed many of the same trends we see in education more generally. And there has been comparable push to provide more “alternatives” for gaining access to principal, supervisor and district leadership credentials. NOTE- if you think some of what I’m displaying here makes education grad degree production look like a cesspool, I assure you that when it comes to the production of MBAs, the picture is equally if not even more ugly! (One can buy an MBA almost anywhere… perhaps even more easily than a degree in ed admin… and in many cases which I have observed directly, the level of academic rigor, even within major universities, is hardly different!)
The figure below shows that major research universities have played a declining role in the production of graduate degrees (all levels) in educational administration. Again, it’s those entrepreneurial LA2s that are crankin’ up the production – moving into 2nd place among institution types.
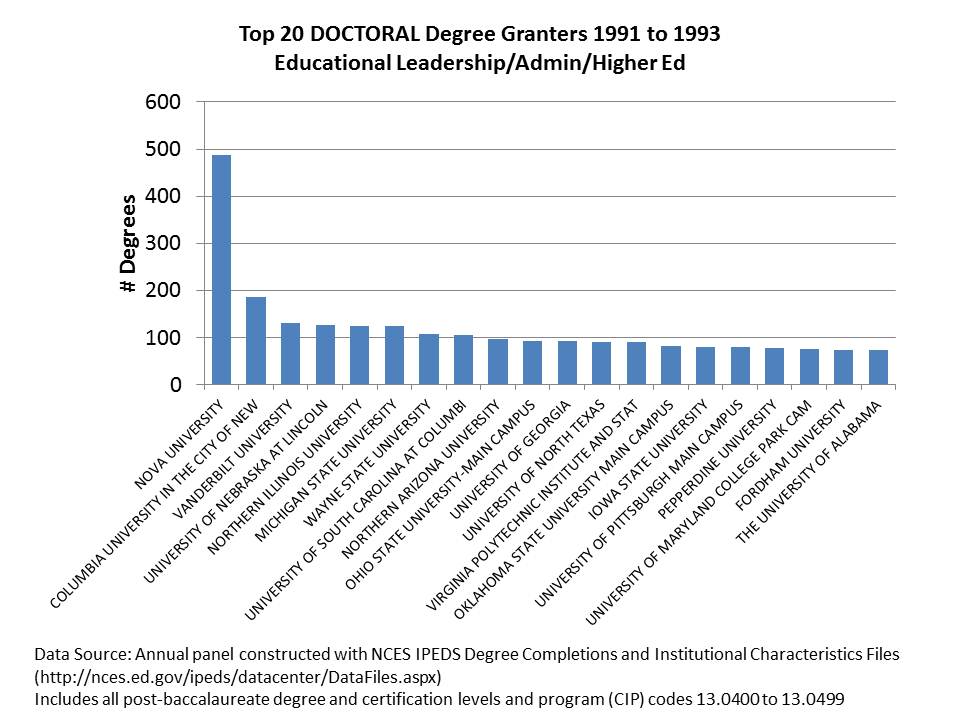
Now lets take a look specifically at doctoral degrees. One can almost kind of understand the mass production masters degrees which in education are often tied to obtaining specific certifications perhaps in additional fields of specialization (special education, etc.). Yes, in many states, administration degrees are structured such that the masters is coupled with building level certification and doctorate with district level certification. Even then, how many doctorates does any one institution need to be cranking out? And who should be granting that level of degree?
By 1990s Carnegie classifications, doctorates should be (have been) largely granted out by Research and Doctoral Universities. Comprehensive colleges were generally masters producing schools, not doctoral granting institutions. These strata were, in fact, intended to reflect the capacity of institutions to grant certain types/levels of degrees.
Already by the early 1990s, Nova Southeastern had pioneered mass production of the education doctorate. But outside of the Nova model, most major producers of doctorates were actual universities (okay… a bit harsh… since NOVA actually is a university, and has a pretty well defined, conventional curriculum for their graduate programs).
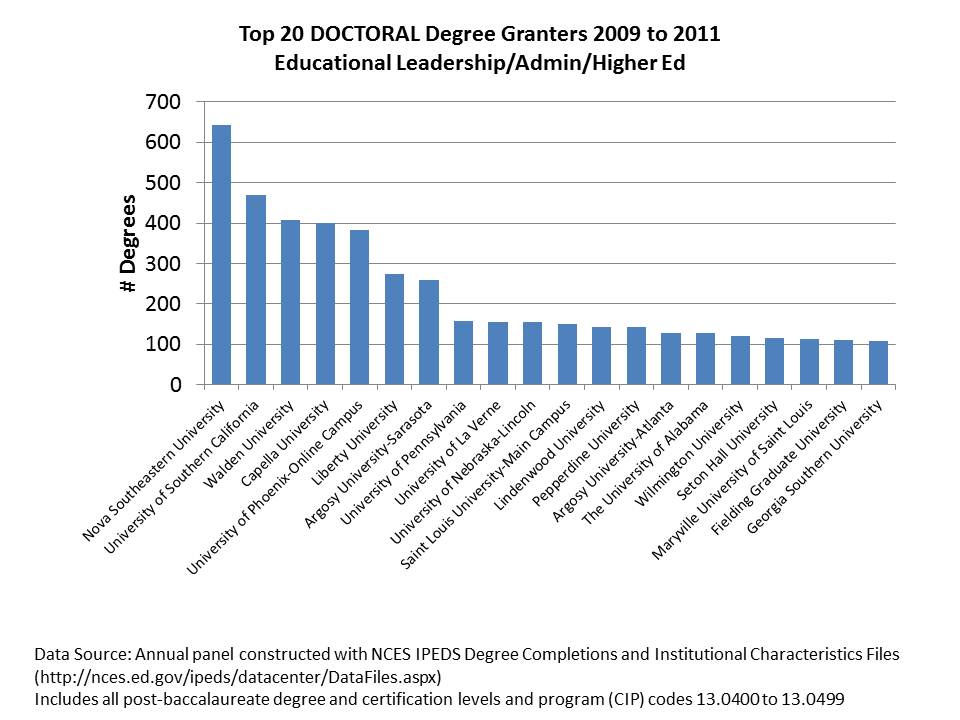
In the most recent years, Nova Southeastern has remained strong… but now right up there are such stellar academic powerhouses as Walden, Capella and Phoenix! (and Argosy)… many of which probably occasionally show up as side-bar advertisements on my blog! (as they do when I log into facebook).
A notable change in the past few years is the entrance of USC and Penn to this mix, with their new practitioner preparation programs which apparently crank out a sizable number of doctorates per year. This raises the interesting question of whether leading universities should try to get into the mass production game? Is the system overall better for it, even if those institutions have to sacrifice some quality in order to mass produce? We’ll have to see if they can keep up with the Waldens and Capellas over the next several years.
Closing Thoughts
To me, these trends are pretty astounding, and serious consideration of these trends must play into any discussion that alarmists might have about the supposed decline in the quality of teacher and administrator preparation (to the extent these alarmists give serious consideration to anything). Those ringing these alarm bells seem more than happy to suggest that the obvious problem lies with traditional “ed schools” (read, regional and state flagship public colleges and universities) and that the obvious solution is to provide more alternative routes, online options – teacher preparation by MOOC… (and likely not a MOOC delivered by Stanford U. faculty… but rather through Walden, Capella and the like) & expansion of schools relying on imported, short term labor supply.
I also find it strange to say the least that those who argue that the problem is that our teachers don’t come from the upper third of college graduates seem to believe that the solution is to expand the types programs that tend to grow most rapidly among colleges that cater to the bottom third (less & non-competitive). To those reformy alarmists who feel they’ve identified the obvious problems and logical solutions, the above data should make sufficiently clear that we’ve already gone down that road.
Further, I’m thoroughly unconvinced that new models purporting to be more selective in the teachers they prepare, but relying largely on a self-credentialing model (we use our teachers to credential our teachers… and only accept as graduate students those who work in our schools?) focused primarily in ideological & cultural indoctrination are a step in the right direction. I have little doubt they’ll find a captive audience to self-credential and maintain a viable “business model,” (by requiring their own teachers to take courses delivered by their peers & bosses to achieve the credentials needed to keep their jobs) but this endogenous, back-patting self-validating model is no way to train the future teacher workforce.*
All of this begs the question of what next? Where do we go from here? How to we achieve integrity and quality in the production of degrees and credentials, and more broadly training and preparation of future teachers and administrators? I really don’t have any answers for these questions right now. But I’m pretty sure that the last two decades have taken us the wrong direction!
Related Research
Baker, B.D, Orr, M.T., Young, M.D. (2007) Academic Drift, Institutional Production and Professional Distribution of Graduate Degrees in Educational Administration. Educational Administration Quarterly 43 (3) 279-318
Baker, B.D., Fuller, E. The Declining Academic Quality of School Principals and Why it May Matter. Baker.Fuller.PrincipalQuality.Mo.Wi_Jan7
Baker, B.D., Wolf-Wendel, L.E., Twombly, S.B. (2007) Exploring the Faculty Pipeline in Educational
Administration: Evidence from the Survey of Earned Doctorates 1990 to 2000. Educational
Administration Quarterly 43 (2) 189-220
Wolf-Wendel, L, Baker, B.D., Twombly, S., Tollefson, N., & Mahlios, M. (2006) Who’s Teaching the Teachers? Evidence from the National Survey of Postsecondary Faculty and Survey of Earned Doctorates. American Journal of Education 112 (2) 273-300
1994 Carnegie Classifications
- Research Universities I: These institutions offer a full range of baccalaureate programs, are committed to graduate education through the doctorate, and give high priority to research. They award 50 or more doctoral degrees1 each year. In addition, they receive annually $40 million or more in federal support.
- Research Universities II: These institutions offer a full range of baccalaureate programs, are committed to graduate education through the doctorate, and give high priority to research. They award 50 or more doctoral degrees1 each year. In addition, they receive annually between $15.5 million and $40 million in federal support.
- Doctoral Universities I: These institutions offer a full range of baccalaureate programs and are committed to graduate education through the doctorate. They award at least 40 doctoral degrees1 annually in five or more disciplines.
- Doctoral Universities II: These institutions offer a full range of baccalaureate programs and are committed to graduate education through the doctorate. They award annually at least ten doctoral degrees—in three or more disciplines—or 20 or more doctoral degrees in one or more disciplines.
- Master’s (Comprehensive) Universities and Colleges I: These institutions offer a full range of baccalaureate programs and are committed to graduate education through the master’s degree. They award 40 or more master’s degrees annually in three or more disciplines. [Includes typical regional, within-state public normal schools/teachers colleges]
- Master’s (Comprehensive) Universities and Colleges II: These institutions offer a full range of baccalaureate programs and are committed to graduate education through the master’s degree. They award 20 or more master’s degrees annually in one or more disciplines.
- Baccalaureate (Liberal Arts) Colleges I: These institutions are primarily undergraduate colleges with major emphasis on baccalaureate degree programs. They award 40 percent or more of their baccalaureate degrees in liberal arts fields4 and are restrictive in admissions.
- Baccalaureate Colleges II: These institutions are primarily undergraduate colleges with major emphasis on baccalaureate degree programs. They award less than 40 percent of their baccalaureate degrees in liberal arts fields4 or are less restrictive in admissions. [Includes many cash-strapped, relatively non-selective, smaller private liberal arts colleges]
*I still like to believe that the most important background attribute of a “good teacher” or school leader is someone who is enthusiastic about their own learning, constantly seeking intellectual growth and challenge and that this attribute is often revealed in the types of advanced studies an individual chooses to pursue. To me, even if the Relay model does tap into a set of graduates of more selective colleges, if the Relay program itself is little more than a workshop on “no excuses” classroom disciplinary practices and typical inspiring edu-guru staff development fodder, then the Relay model is antithetical to developing truly good teachers. A workshop or two and perhaps some practical guidance from peers or teacher leaders – okay. But a graduate degree based on this stuff? Are you kidding? (just watch the RELAY GSE Videos here: http://www.relayschool.org/videos?vidid=5)































{kind=link}
{kind=link}