Many of the “reformers” out there are whining and fist-thumping about the surprise omission of Louisiana and Colorado as Race to the Top Winners. After all, Louisiana has been a heavy favorite from the outset of RttT, and Colorado… well Colorado took the amazingly bold leap of adopting legislation to mandate that a majority of teacher evaluation be based on value-added test scores. That’s got to count for something. Heck, these two states should have gotten the whole thing? Here’s Tom Vander Ark’s take on this huge surprise loss: http://edreformer.com/2010/08/co-la-surprise-losers/
Now here’s why I find it somewhat of a relief that these two states did not find themselves in the winners’ circle (not that I can identify a great deal of logic to support those who did… but…).
I’ve written numerous times about Louisiana’s public education system, and that state’s support or lack-thereof for providing a decent quality education for the children of Louisiana.
https://schoolfinance101.wordpress.com/2009/12/18/disg-race-to-the-top/
Here’s an excerpt from that previous post:
Let’s take a look at Louisiana’s education system. Yes, their system needs help, but the reality is that Louisiana politicians have never attempted to help their own system. In fact they’ve thrown it under the bus and now they want an award? Here’s the rundown:
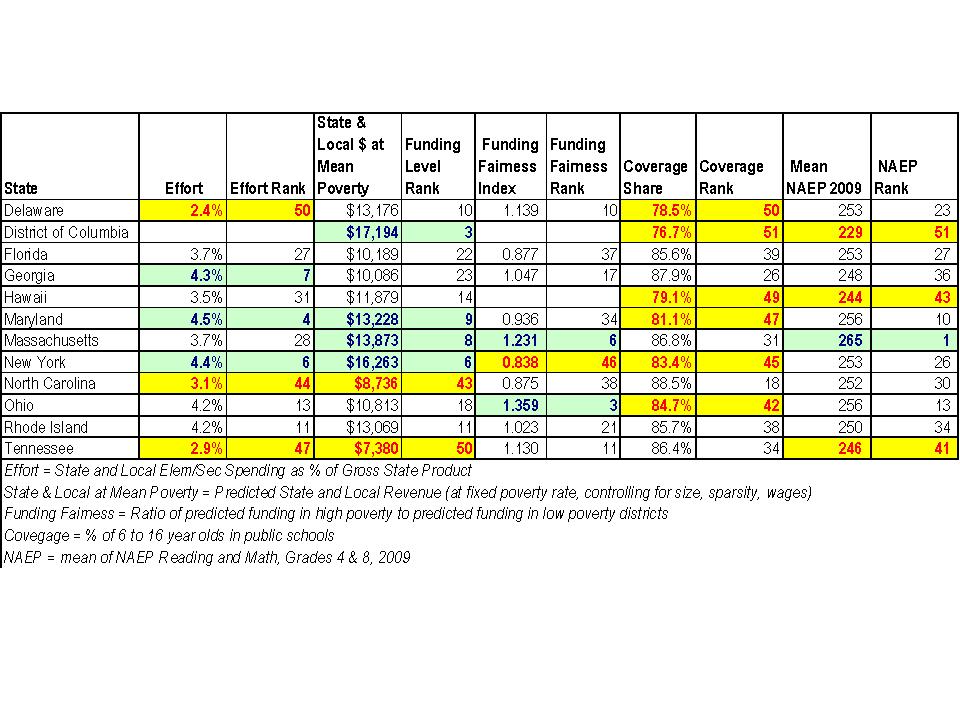
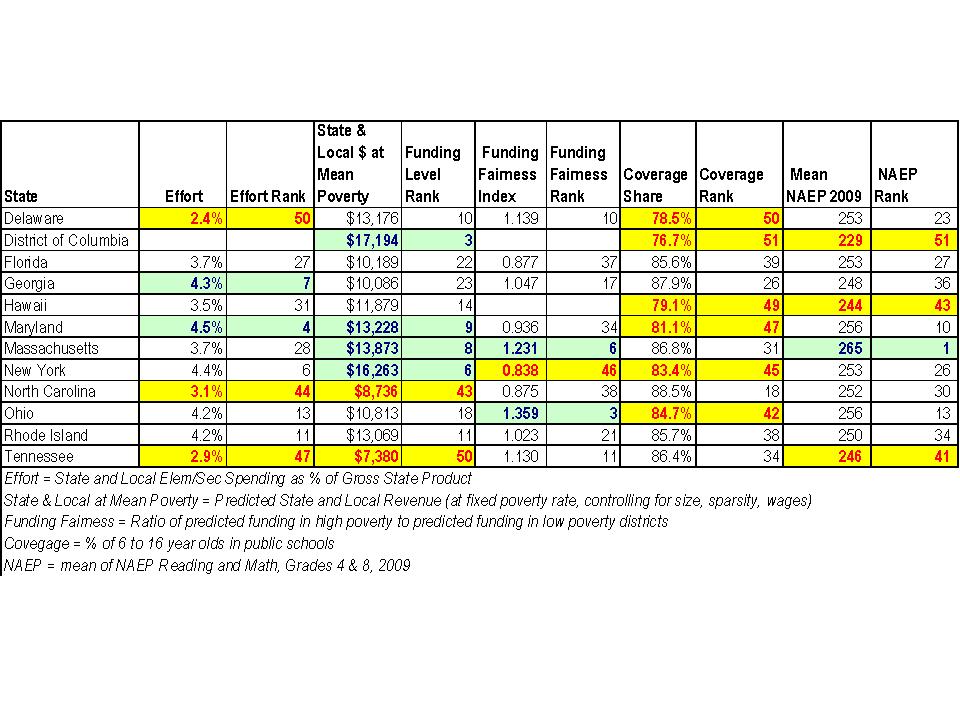
- 3rd lowest (behind Delaware & South Dakota) % of gross state product spent on elementary and secondary schools (American Community Survey of 2005, 2006, 2007)
- 2nd lowest percent of 6 to 16 year old children attending the public system at about 80% (tied with Hawaii, behind Delaware) (American Community Survey of 2005, 2006, 2007). The national average is about 87%.
- 2nd largest (behind Mississippi) racial gap between % white in private schools (82%) and % white in public schools (52%) (American Community Survey of 2005, 2006, 2007). The national average is a 13% difference in whiteness, compared to 30% in Louisiana.
- 3rd largest income gap between publicly and privately schooled children at about a 2 to 1 ratio. (American Community Survey of 2005, 2006, 2007)
- 4th highest percent of teachers who attended non-competitive or less competitive (bottom 2 categories) undergraduate colleges based on Barrons’ ratings (NCES Schools and Staffing Survey of 2003-04). Almost half of Louisiana teachers attended less or non-competitive colleges, compared to 24% nationally.
- Negative relationship between per pupil state and local revenues and district poverty rates, after controlling for regional wage variation, economies of scale, population density (poor get less).
- 46th (of 52) on NAEP 8th Grade Math in 2009. 38th of 41 in 2000. http://nces.ed.gov/nationsreportcard/statecomparisons/
- 49th (of 52) on NAEP 4th Grade Math in 2009. 35th of 42 in 2000.
So, this is a state where 20% abandon the public system and 82% of those who leave are white and have income twice that of those left in the public system, half of whom are non-white. While the racial gap is large in Mississippi, a much smaller share of Mississippi children abandon the public system and Mississippi is average on the percent of GSP allocated to public education. Mississippi simply lacks the capacity to do better. Louisiana doesn’t even try. And they deserve and award?
Quite honestly, I hadn’t really thought much about Colorado’s chances until today. I was certainly aware of their finalist status and aware of the reform crowd support for their new teacher evaluation legislation. But I hadn’t really reviewed their “indicators.” Here’s my summary of Colorado from earlier today:
Using 2007-08 data, Colorado ranks:
- 45th in effort (% gross state product spent on schools)
- 39th in funding level overall
- 32nd in funding fairness (has a system whereby higher poverty districts have systematically less state and local revenue per pupil than lower poverty districts)
Yes, better than Louisiana, but nothin’ to brag about. And yes, both are marginally better than Round 1 winner Tennessee… but nearly every other state in the nation is.
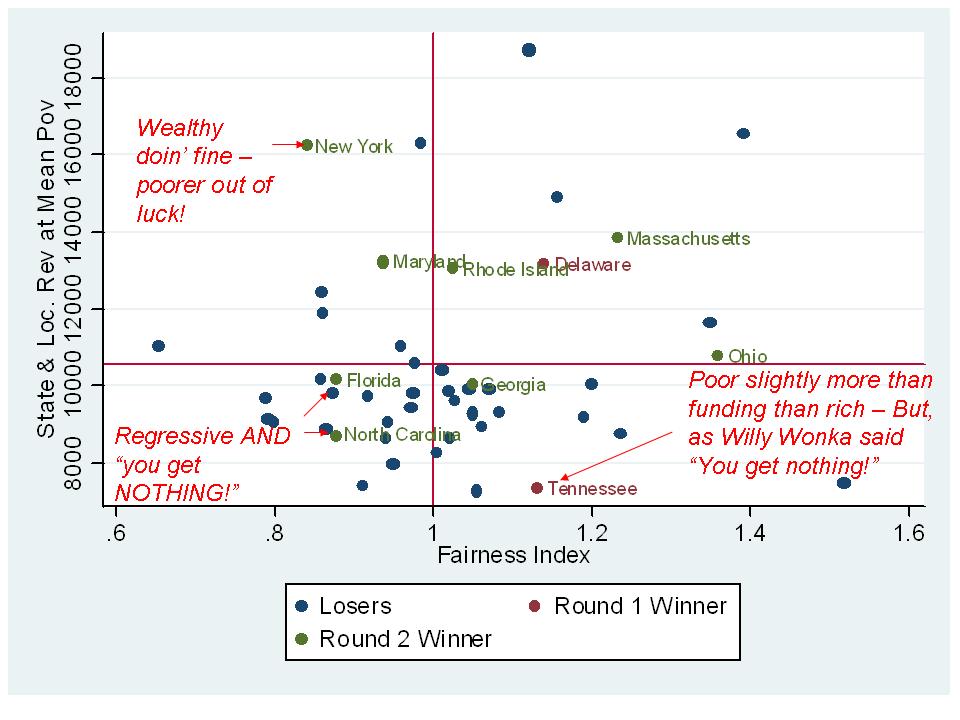
So, where do these two states fit into those scatterplots I posted earlier today which identified Round 1 and Round 2 winners? Here they are – First, fiscal effort and overall spending level. Both states are very low effort states, and both are relatively low spending states.
 And next, effort and funding fairness – or the extent to which funding is allocated in greater amounts to districts with greater needs.
And next, effort and funding fairness – or the extent to which funding is allocated in greater amounts to districts with greater needs.
 In both cases, Louisiana and Colorado fall toward the lower left hand corner of the plot. Both are very low fiscal effort states. They have the capacity to provide more support for public education – BUT DON’T! Both states are also “regressive” – allocating systematically less funding per pupil to higher need districts, with Louisiana close to a flat distribution. And both are generally low spending despite their capacity to do better.
In both cases, Louisiana and Colorado fall toward the lower left hand corner of the plot. Both are very low fiscal effort states. They have the capacity to provide more support for public education – BUT DON’T! Both states are also “regressive” – allocating systematically less funding per pupil to higher need districts, with Louisiana close to a flat distribution. And both are generally low spending despite their capacity to do better.
Improving state data systems – linking those data to teacher preparation institutions in order to impose sanctions on those institutions – banning teachers from obtaining tenure until they can achieve 3 consecutive years of positive value-added scores (error rates alone and year to year fluctuations may make this a low probability event) – and expanding charter schools are not likely to dig these states out of their current position. Doing so will require far greater investment than RttT could ever provide, especially in the case of Louisiana. In fact, dramatically increasing job risk and career instability for individuals interested in entering teaching without also increasing the reward is likely to have significant negative effects. Unfortunately, it is about as likely that losing RttT will cause these states to reconsider their shortsighted reform agendas as it is that reading this blog post will get them to reconsider the persistent deprivation of their public education systems.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}